Your new post is loading...
Your new post is loading...
La deep tech nantaise a développé une technologie unique d'anonymisation de données qu’elle déploie déjà sur le secteur de la santé. Si une collaboration vient d’être nouée avec le Health Data Hub pour démocratiser l’utilisation des données synthétique auprès des acteurs de ce marché, Octopize regarde aussi d’autres marchés.
Via Lionel Reichardt / le Pharmageek
L' exploration de données, connue aussi sous l'expression de fouille de données, forage de données, prospection de données, data mining , ou encore extraction de connaissances à partir de données, a pour objet l'extraction d'un savoir ou d'une connaissance à partir de grandes quantités de données, par des méthodes automatiques ou semi-automatiques.
In 2020, OVHcloud launched a portfolio of PaaS solutions dedicated to Data and AI. As an innovative cloud player for the past 20 years, our up-to-date technology coupled with our close collaboration with data science communities as well as the most cutting-edge players in the sector has enabled us to identify 10 strong AI trends … 2021: major technological advances to accelerate, democratize and certify AI uses Read More »
In our previous blog post about observability, we explained how to build a comprehensive view of how your SQL workloads behave, and the many reasons why it is important to have this view. In this blog post, we will take a closer look into the four types of SQL query, and how they can impact … Explaining slow queries to my manager Read More »
Percona's Peter Zaitsev discusses some of the best practices for configuring optimal MySQL memory usage.
Vous lirez beaucoup de traductions plus ou moins déformées de cette expression. Mot à mot « Event Scheduler » signifie programmateur d'évènements. Ce processus (interne au moteur) déclenche des évènements en fonction de la date et de l'heure auxquelles ils sont programmés. Ce sont donc des déclencheurs temporels (en anglais triggers) qui vont ordonner l'exécution de l'évènement. L'évènement réalise une combinaison de procédures stockées ou de une à plusieurs requêtes SQL programmées par l'utilisateur. Le déclenchement peut être périodique et se lancer de une à plusieurs fois.
Ce tutoriel est un cours pour vous apprendre à améliorer les performances grâce au partitionnement (MySQL 5.1)
Utilisation avancée des procédures stockées MySQL .
Jet Profiler de Polaricon est un outil permettant d'identifier des goulots de performance dans les bases MySQL. Il s'agit d'une application bureautique qui récolte une variété de statistiques d'une base de données en cours. Il est compatible avec Windows, Mac et Linux. MySQL étant habituellement associé aux sites web, Jet Profiler est donc utilisé plus souvent pour mesurer la performance des sites. Il peut être utilisé pour analyser la performance d'une application écrite pour MySQL.
Retour d'expérience sur la mise en oeuvre du BigData chez PagesJaunes.fr
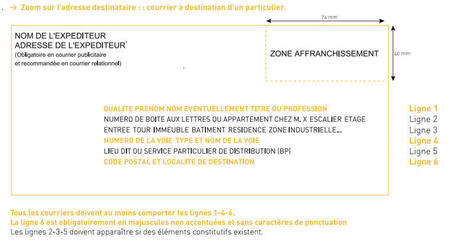
Illustration règles normes françaises
Quelques règles de la norme de l'adresse française
Format de l'adresse :
6 lignes de 38 caractères maximum (éventuellement une 7ème ligne pour l’international, pour indiquer le pays).
Les lignes à blanc – non renseignées – sont supprimées pour rendre l’adresse plus esthétique.
L’adresse est alignée à gauche, ce qui facilite la lecture optique mécanisée des adresses par La Poste.
Caractères tolérés par la norme Afnor NF Z 10-011 :
A partir de la ligne 4 (numéro et libellé de la voie), aucune ponctuation, italique ou souligné qui perturbent la lecture automatique des adresses.
Par ailleurs, la norme veut que seule la dernière ligne soit en majuscule, mais La Poste recommande vivement une mise en majuscule des 3 dernières lignes adresses (voie / lieux-dits ou Boite Postale / Code Postal Commune), afin d’optimiser significativement la reconnaissance des adresses par les lecteurs optiques des centres de traitement de courriers.
Présentation de l’adresse selon la norme Afnor NF Z 10-011 :
Les éléments de l’adresse doivent être ordonnés selon une structure bien précise
Adresse B TO C après RNVP
1.Civilité - Titre ou Qualité - Prénom - Nom
2.N°APP ou Bal - étage - Couloir - Esc
3.Entrée - Bâtiment - Immeuble - Résidence
4.Numéro - Libellé de la voie
5.Lieu dit ou Service particulier de distribution
6.Code postal et Localité de destination
ou Code Cedex et Libellé Cedex
Adresse B TO B après RNVP
1. raison sociale ou dénomination
2. identité du destinataire et ou service
3. Entrée - Bâtiment - Immeuble - Rés - ZI
4. Numéro - Libellé de la voie
5. mention spéciale et commune géographique
6. Code postal et Localité de destination
ou Code Cedex et Libellé Cedex
Source SNA (Service National de l’Adresse – Groupe La Poste)
Machine Learning and especially Deep Learning are hot topics and you are sure to have come across the buzzword “Artificial Intelligence” in the media. Yet these are not new concepts. The first Artificial Neural Network (ANN) was introduced in the 40s. So why all the recent interest around neural networks and Deep Learning? We will explore this … Deep Learning explained to my 8-year-old daughter Read More »
Le nom Redis vient de Remote Dictionary Server. Ce type de serveur est idéal lorsqu’il est utilisé comme mémoire de données rapide. Le système de gestion de base de données (SGBD) Redis propose également une base de données en mémoire et un système clé-valeur.
Base de données en mémoire : ces bases de données permettent au SGBD d’enregistrer toutes les données directement dans la mémoire vive. Ceci permet des délais d’accès très courts – même en cas de grands volumes de données non structurées.
Système clé-valeur : les bases de données clé-valeur séduisent par leur performance élevée et leur possibilité de mise à l’échelle grâce à une structure simple. Une clé permettant de consulter les informations a posteriori est créée pour chaque entrée.
Dans le cas d’un serveur Redis, toutes les données ne sont donc pas situées sur le disque dur, mais dans la mémoire vive. Du fait de ce choix, Redis est aussi bien une mémoire cache qu’une mémoire vive : Redis ne fait aucune distinction entre les informations stockées dans la base de données durablement ou uniquement à court terme.
Chaque entrée de la base de données se voit attribuer une clé. Elle permet de consulter les données ultérieurement en toute simplicité. Les entrées ne sont donc pas liées les unes aux autres et ne doivent donc pas être interrogées dans plusieurs tableaux. Les informations sont directement disponibles.
Du fait de l’enregistrement dans la mémoire vive, il existe toutefois un risque de perte de l’ensemble des données en cas de panne du serveur. Afin d’éviter cela, Redis peut soit dupliquer régulièrement toutes les données sur un disque dur de sauvegarde soit enregistrer toutes les commandes nécessaires à une reconstruction dans un fichier journal.
|
On trouve différents tutoriels, la plupart en anglais, au sujet de la création d'un database_link dans Oracle pour accéder à une base MySQL. L'un parle du cas spécifique de l'accès à une base MariaDB mais ses exemples de code m'ont posé quelques soucis de compréhension entraînant par la suite un refus de fonctionnement et quelques prises de tête pendant pas mal de temps.
Je vais donc décrire ici pas à pas ce qu'il faut faire pour que ça fonctionne.
L’entrepôt de données traditionnel arrive-t-il en fin de vie ? Dans l’affirmative, quelle solution hybride pourrait lui succéder ? Ces questionnements laissent apparaître plusieurs évolutions possibles du data warehousing et poussent les entreprises à choisir leur(s) voie(s).
where we explain machine learning concepts and how to get started using it, for real.
Ci-dessous les 6 règles d'or de la norme postale selon le SNA :
Source image : SNA
Dans un sens plus courant, la normalisation postale désigne l'opération qui consiste à vérifier et remettre à la norme postale les adresses d'un fichier avant une opération de marketing direct. Le but est alors de réduire les coûteux PND anciennement appelés NPAI et de bénéficier de tarifs postaux spécifiques. La normalisation postale se fait généralement dans le cadre d'un traitement dit traitement RNVP.
Un exemple de procédure de normalisation d'une adresse postale :
Source image : Cartégie
Dans cet article, nous discutons des fonctionnalités XML disponibles dans MySQL, avec l'accent sur les nouvelles fonctionnalités des versions 5.1 et 6.0.
Nous partons du principe que vous avez déjà des connaissances sur XML et que vous savez ce que les termes « valide » et « bien formé » veulent dire.
Nous supposons aussi que vous ayez quelques connaissances sur XPath.
Nous allons couvrir ces différents sujets :
les méthodes pour exporter des données MySQL dans le format XML, incluant l'utilisation de lib_MySQLudf_xql, une librairie tierce qui peut être utilisée pour cette tâche ;
l'utilisation des fonctions (nouvelles dans MySQL 5.1) ExtractValue() et UpdateXML() pour travailler avec XML et Xpath ;
le stockage de données depuis XML dans une base MySQL en utilisant la déclaration LOAD XML (implémentée dans MySQL 6.0) ;
quelques éléments de sécurités à garder à l'esprit quand on utilise ces techniques
Depuis la version 5, MySQL supporte la programmation intégrée (ou SQL procédural), qui permet de le rendre très autonome. Nous verrons dans cet article quelles sont les possibilités qui s'offrent à nous pour reporter la programmation sur le SGBD. Je ne prétends pas aborder toutes les possibilités du SQL procédural, mais seulement proposer une des très nombreuses utilisations que l'on peut en faire. Ce tutoriel peut constituer une introduction au SQL procédural pour les débutants, et une solution efficace de gestion d'erreurs pour les plus confirmés. ♪
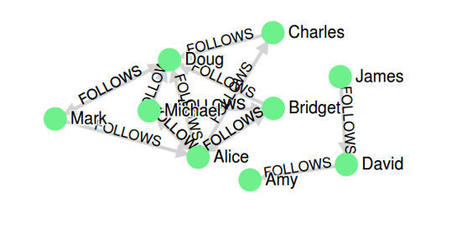
In the past couple of years, the field of data science has gained much traction. It has become an essential part of business and academic research. Combined with the increasing popularity of graphs…
Read this book to:
Register to Download O'Reilly's Graph Algorithms for Free!
Learn how graph analytics vary from conventional statistical analysis
Understand how classic graph algorithms work and how they are applied
Dive into popular algorithms like PageRank, Label Propagation and Louvain to find out how subtle parameters impact results
Get guidance on which algorithms to use for different types of questions
Explore algorithm examples with working code and sample datasets for both Apache Spark and Neo4j
See how connected feature extraction increases machine learning accuracy and precision
Walk through creating an ML workflow for link prediction combining Neo4j and Apache Spark
Quotation
Discover how graph algorithms help you leverage the relationships within your data to develop more intelligent solutions and enhance your machine learning models.
PostgreSQL allows you to store and compare UUID values, but it doesn't have any built-in methods for creating them. This is why this post was developed - to show you several ways to generate UUIDS in Postgres.
La Norme 32 est morte. Vive la norme 38…
En 1997, l’AFNOR avait créé une norme pour faciliter le traitement du courrier, son acheminement et les tarifs postaux pour des envois en nombre.
Par souci d’harmonisation européenne, une nouvelle norme est entrée en vigueur le 19 janvier 2013 et porte le doux nom de NF Z 10-011.
Cette nouvelle prendra définitivement la place de l’ancienne norme (les deux normes étant jusque-là gérées simultanément) à compter du 1er novembre 2015.
Ce qui change…
Le tri postal se fait de bas en haut. Donc du général vers le particulier. En conséquence, vous devez libeller vos adresses de la même façon : nom de la personne (Madame DENIS par exemple), complément d’informations d’un bâtiment (porte 2 par exemple), complément d’information dans la voie (bâtiment A par exemple), voie principale (2 rue de Paris), lieu-dit (Les Carrières par exemple), code postal/ville.
6 lignes au maximum sans ligne vierge.
38 caractères maximum par ligne, espaces compris. Un espace doit figurer entre chaque mot. Une abréviation n’est autorisée que lorsque le libellé de la voie dépasse 38 caractères.
There are 3 major types of database models in use today. In this post, learn about their differences and what applications for which they are best suited.
A curated list of Google Sheets resources to supercharge your analysis, manage your workflow, or build expertise in advanced analytics.
Via Frédéric DEBAILLEUL
|